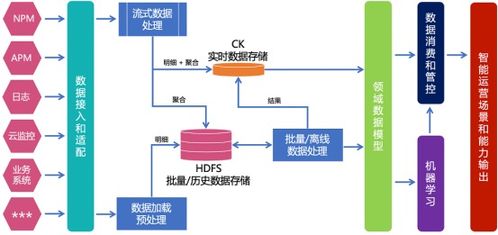
随着金融行业数字化转型的深入,业务系统日益复杂,运维监控面临海量、异构、实时性要求高的数据挑战。构建统一监控体系已成为金融机构保障系统稳定、提升运营效率的必然选择,而运维数据治理则是这一体系的核心支柱。其中,数据处理服务作为治理落地的关键环节,直接关系到监控数据的质量、价值与可用性。
一、统一监控对运维数据治理的核心诉求
金融行业的统一监控旨在实现对基础设施、应用性能、业务交易、安全态势等的全景可视与智能分析。这要求运维数据必须具备:
- 统一性:来自网络设备、服务器、数据库、中间件、应用日志、业务指标等多源数据,需在格式、模型、语义上实现统一。
- 准确性:数据必须真实、完整、及时,任何失真或延迟都可能引发误判,影响风控与决策。
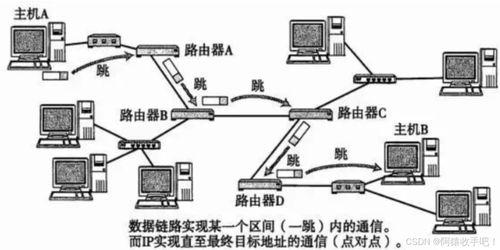
- 关联性:能够跨系统、跨层级进行关联分析,快速定位根因,例如将应用延迟与底层资源瓶颈相关联。
- 合规性:需满足金融监管机构对数据安全、隐私保护、审计留痕等方面的严格规定。
二、数据处理服务在运维数据治理中的核心功能
为满足上述诉求,专业的数据处理服务需提供以下核心能力:
- 数据采集与接入:支持Agent、API、日志抓取、流量镜像等多种方式,适配各类数据源,实现全量、实时、无损采集。
- 数据解析与标准化:对非结构化、半结构化日志进行智能解析(如正则解析、GROK模式),提取关键字段,并映射到统一的监控数据模型(如基于OpenTelemetry的标准)。
- 数据清洗与增强:过滤无效、重复数据,修复缺失值,并通过IP地理信息库、CMDB配置库等进行数据丰富,补充上下文信息。
- 数据关联与聚合:基于时间戳、交易ID、主机IP等关键字段,实现跨源数据的关联;按时间窗口、业务维度进行实时聚合,生成高阶指标(如成功率、平均响应时间)。
- 实时流处理与计算:利用Flink、Spark Streaming等引擎,对数据流进行实时过滤、转换、统计与告警阈值计算,满足秒级监控需求。
- 数据路由与分发:将处理后的数据高效、可靠地分发给下游的监控分析平台、告警引擎、数据仓库或AIOps平台,支撑不同场景的消费。
三、金融行业数据处理服务的实施路径
- 制定数据规范与模型:首先定义企业级统一监控数据模型,明确数据分类、核心字段、质量标准与生命周期,这是所有处理流程的基准。
- 构建可扩展的管道架构:采用微服务化、容器化的数据处理流水线,实现采集、解析、清洗、计算等环节的解耦与弹性伸缩,以应对业务峰值。
- 嵌入数据质量监控:在数据处理各环节设置质量检查点,监控数据流量、延迟、解析成功率、字段完整性等,实现数据质量的闭环管理。
- 强化安全与合规控制:对敏感信息(如用户ID、交易金额)进行实时脱敏;确保数据处理过程符合内部合规与外部监管要求,并保留完整的审计日志。
- 与运维流程集成:将数据处理服务与事件管理、变更管理、容量规划等ITSM流程打通,使高质量数据能直接驱动运维决策与行动。
四、未来展望:向智能与主动运维演进
随着技术发展,数据处理服务将进一步融合机器学习能力,实现:
- 智能解析:自动学习日志模式,适应应用变更,减少人工维护成本。
- 异常检测:在数据流中实时识别潜在异常模式,实现主动预警。
- 根因分析:自动关联多维度数据,快速定位故障根源。
在金融行业统一监控的宏大架构中,运维数据治理是基石,而健壮、高效、智能的数据处理服务则是将原始数据转化为运维洞察的“核心引擎”。金融机构需从战略高度规划其建设,通过标准化的模型、自动化的流程、持续的质量管理,确保监控数据可信、可用、有价值,最终赋能业务稳定与创新。